
Una base de datos desprotegida, propiedad de IDMerit, y que probablemente
contiene datos de KYC, ha filtrado grandes
cantidades de registros personales en varios países, incluyendo Estados
Unidos, Alemania, Francia, China, Brasil y muchos más.

¿Quién es IDMerit y cómo ocurrió esto?
El equipo de CyberNew cree que la base de datos expuesta pertenece a IDMerit, un proveedor de
soluciones de verificación de identidad digital basadas en IA. La empresa
presta servicios a los sectores de tecnología financiera y servicios
financieros, ayudando a las empresas con herramientas de verificación en
tiempo real. Las prácticas KYC (Conozca a su Cliente) son una norma global
para que los usuarios verifiquen sus identidades al configurar diversas
cuentas.
Los investigadores detectaron la instancia expuesta el 11 de noviembre de 2025
y contactaron inmediatamente con la empresa, que protegió rápidamente la base
de datos. Si bien no hay evidencia actual de uso indebido malicioso, los
rastreadores automatizados configurados por los actores de amenazas rastrean
constantemente la web en busca de instancias expuestas, descargándolas casi
instantáneamente en cuanto aparecen.
La información filtrada incluye una gran cantidad de información personal
identificable (PII), incluyendo nombres completos y direcciones, así como
documentos nacionales de identidad y números de teléfono. La instancia de
MongoDB expuesta contenía varias bases de datos que abarcaban a personas de 26
países, lo que convierte la filtración de datos en algo verdaderamente global.
¿Qué datos personales se filtraron?
Dado que IDMerit es un proveedor de KYC (Conozca a su cliente) basado en IA,
los datos que recopila son extremadamente sensibles.
La base de datos de 1 terabyte, sin protección, no solo filtró contraseñas,
sino también los identificadores personales esenciales que utiliza para su
vida financiera y digital.
Los siguientes datos estructurados quedaron a disposición de cualquiera:
- Nombres completos
- Direcciones
- Códigos postales
- Fechas de nacimiento
- Documentos de identidad nacionales
- Números de teléfono
- Género
- Direcciones de correo electrónico
- Metadatos de telecomunicaciones
- Estado de la filtración y anotaciones en perfiles sociales
El último dato (estado de la filtración y anotaciones en perfiles sociales)
podría referirse a un identificador de base de datos que indica si los datos
provienen de una filtración o de una base de datos filtrada. Sin embargo, en
este momento, el verdadero significado de este dato no está claro. El equipo
observó que este dato específico solo estaba presente en algunas regiones.
A esta escala, los riesgos posteriores incluyen robo de cuentas, phishing
dirigido, fraude crediticio, intercambio de tarjetas SIM y daños a la
privacidad a largo plazo. A nivel de toda la industria, el caso pone de
relieve cómo los proveedores de identidad externos se han convertido en
infraestructuras críticas y pueden convertirse en puntos únicos de fallo
catastrófico.
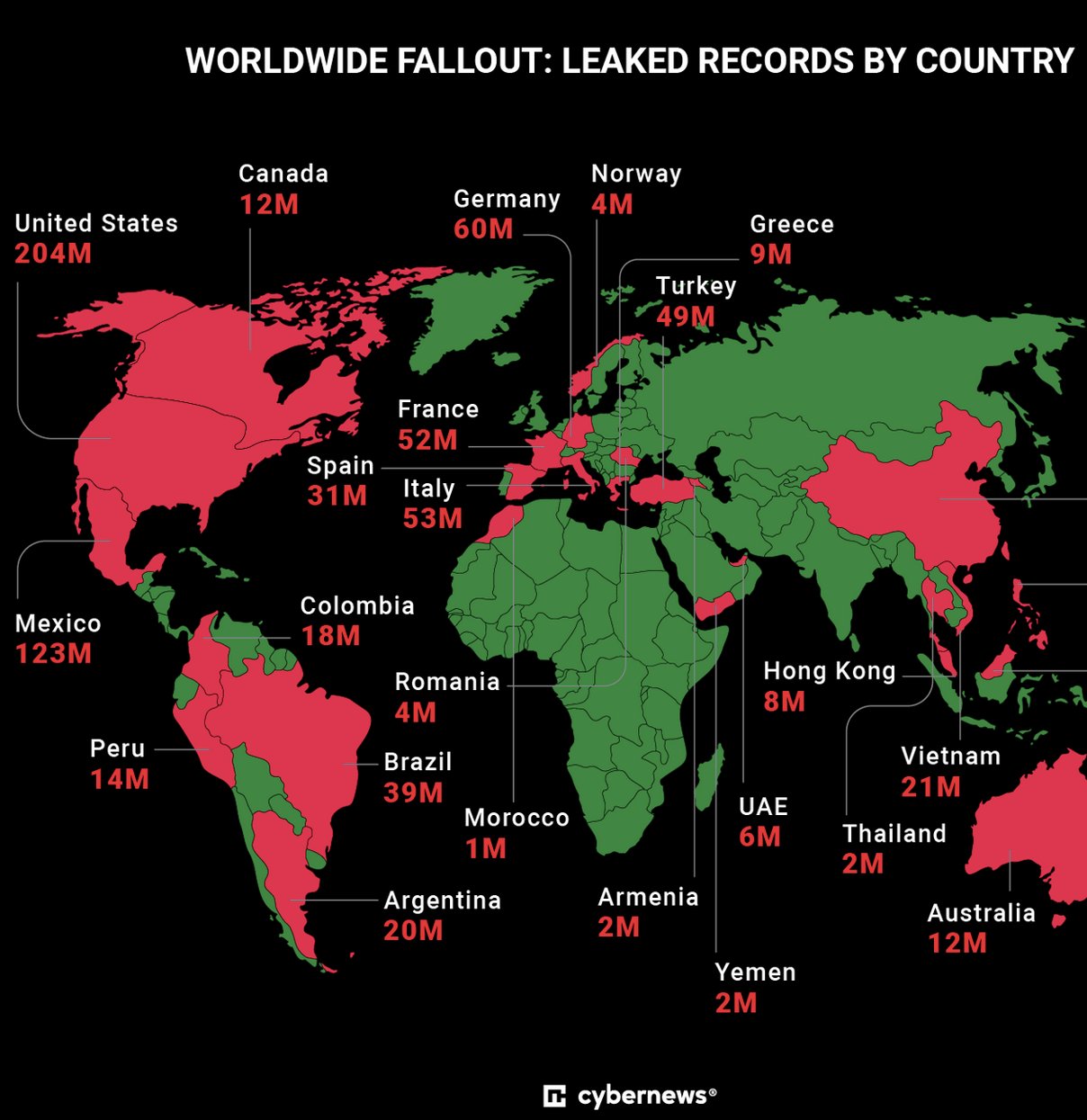
Fuga global de datos abarca varios países
Lo más sorprendente de la fuga de datos de IDMerit es su magnitud y su alcance
global, con tres mil millones de registros que abarcan más de 20 países.
Varias bases de datos parecían contener fragmentos superpuestos para el mismo
país. Sin embargo, el equipo de investigación cree que la mayoría de los
registros eran únicos.
El país con más registros expuestos fue Estados Unidos, con más de 203
millones de registros filtrados. A EE.UU. le siguieron México (124 millones) y
Filipinas (72 millones). Tras los tres primeros, se encuentran tres países
europeos: Alemania (61 millones), Italia (53 millones) y Francia (53
millones).
De los 3 mil millones de registros expuestos, mil millones se atribuyen a
varios países y es probable que revelen datos confidenciales. Otros 2 mil
millones probablemente sean registros de bases de datos, que probablemente
sean menos confidenciales.
«Desde la perspectiva de un atacante, la base de datos incluye
identificadores de alto riesgo: varias regiones incluyen documentos de
identidad nacionales, fechas de nacimiento completas y datos de contacto,
que son ingredientes clave para el robo de identidad, el intercambio de
tarjetas SIM y los ataques de ingeniería social», afirmaron los investigadores.
Además, los actores de amenazas valoran los datos bien estructurados, ya que
les permite automatizar fácilmente campañas a gran escala. La dedicación a la
estructuración de datos es tan sólida que los atacantes pasan meses
recopilando detalles mucho menos amenazantes, solo para compartirlos en foros
de filtración de datos para obtener mayor influencia.
Los investigadores también señalan que los tipos de datos expuestos difieren
entre regiones, lo que crea riesgos específicos para cada una. Por ejemplo,
los registros de Brasil «prefill» incluyen indicadores de perfil social
e «databreachesinfo», lo que podría facilitar el fraude selectivo.
Mientras tanto, varios países tenían recopilaciones de «idmtelco», lo
que sugiere un enriquecimiento centrado en el teléfono y una posible conexión
con conjuntos de datos de telecomunicaciones. Esto aumenta el riesgo de que
las personas expuestas sufran un intercambio de SIM, un tipo de fraude en el
que un delincuente se hace con el control de su número de teléfono móvil.
¿Por qué esta filtración es diferente?
A diferencia de las filtraciones tradicionales de solo correos electrónicos,
esta base de datos está estructurada. Esto permite a los atacantes usar sus
propias herramientas de IA para:
-
Ejecutar intercambios de SIM. Usar su documento nacional de identidad y
metadatos de la compañía de telecomunicaciones para secuestrar su número de
teléfono e interceptar códigos de seguridad. -
Lanzar phishing selectivo. Los estafadores pueden usar su domicilio real y
número de identificación para crear mensajes fraudulentos muy convincentes. -
Evitar las comprobaciones de identidad. Dado que estos datos se recopilaron
con fines KYC, los delincuentes pueden intentar usarlos para suplantar la
identidad de las víctimas en otras plataformas financieras.
La filtración de miles de millones de registros se está volviendo algo
habitual.
La semana pasada, se publicó un clúster de Elasticsearch expuesto que contenía
más de 160 índices y
albergaba 8.700 millones de registros, principalmente chinos, que abarcaban desde números de identificación
nacional hasta diversos registros comerciales.
En diciembre pasado, el equipo descubrió una base de datos desprotegida con
4.300 millones de registros, algunos de los cuales incluían
información personal derivada de LinkedIn. La instancia, de 16 TB de capacidad, contenía correos electrónicos, fotos,
historiales laborales y otros datos personales. Una sola colección contenía
732 millones de registros, incluyendo fotografías.
En julio, Cybernews informó sobre una de las mayores filtraciones de datos de
la historia, después de que investigadores descubrieran varias
colecciones de credenciales de inicio de sesión con 16.000 millones de
registros. El equipo encontró 30 conjuntos de datos expuestos, cada uno con entre
decenas de millones y más de 3.500 millones de registros.
Los datos filtrados incluían información de inicio de sesión para
prácticamente todos los servicios en línea, como Apple, Facebook, Google,
GitHub, Telegram e incluso plataformas gubernamentales.
Fuente:
CyberNews