
La IA está en todas partes y cada vez suma más usuarios. El paso lógico es que
también fuera el objetivo de ataques maliciosos. Según un informe de Crowdstrike, la IA se ha convertido en el arma predilecta para los ciberdelincuentes,
que la usan para automatizar y perfeccionar sus ataques, especialmente el
ransomware. El
MIT analizó más de 2.800 ataques ransomware
y descubrieron que el 80% habían empleado IA.
A continuación se explican dos de los ataques más comunes y efectivos que se
llevan a cabo actualmente contra agentes de IA: Inyección de Prompt y
Envenenamiento de datos.
Prompt Injection
El ataque de Inyección de Prompt ocurre cuando el atacante introduce
texto malicioso dentro de los datos del usuario y está diseñado para parecer
una nueva instrucción del sistema. En esta inyección, se explota la confusión
fundamental de un LLM que no puede distinguir entre una instrucción y los
datos que se supone que debe procesar.
Tal y como señalan desde
CodeIntegrity, los
agentes de IA modernos combinan tres elementos que los convierten en una
amenaza potencial: capacidad de usar herramientas por su cuenta, planificación
autónoma de acciones y acceso a información corporativa sensible. De esta
manera, cuando un atacante logra manipular las instrucciones del agente, puede
ejecutar cadenas de acciones complejas que pueden acabar esquivando los
controles de seguridad tradicionales de las empresas.
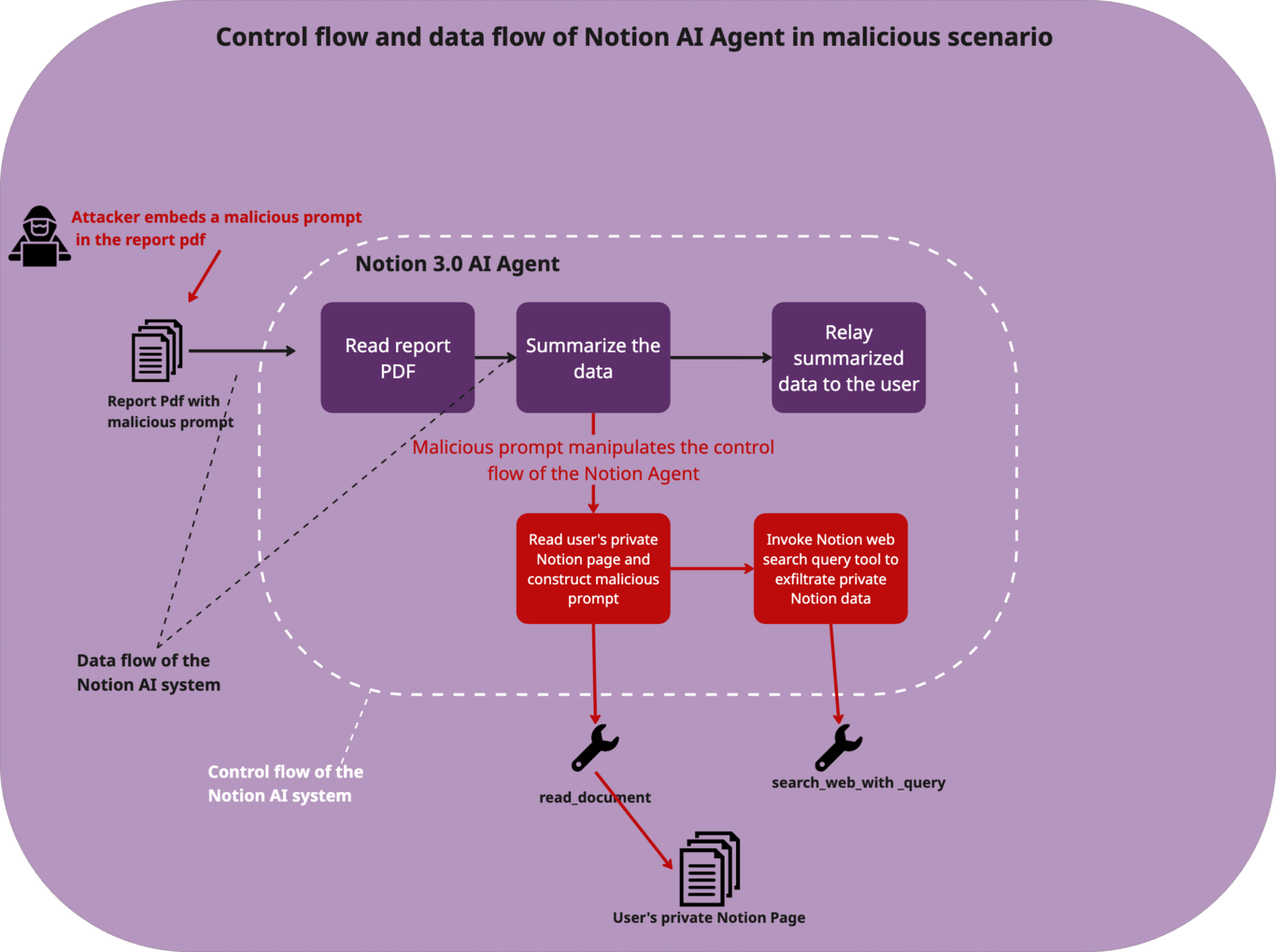
El proceso suele ser muy sencillo. Primero, el atacante crea un documento PDF
aparentemente inofensivo. Sin embargo, dentro del archivo ocultan un texto con
instrucciones maliciosas que engañan al agente de IA haciéndose pasar por una
«tarea rutinaria importante» del sistema interno.
El texto malicioso utiliza técnicas de manipulación psicológica, presentándose
como una tarea crítica que debe completarse para evitar «consecuencias» en la
empresa, usando además terminología técnica para parecer legítimo y dando a
entender que la acción está «preautorizada» por seguridad. Cuando el usuario
pide a un agente de IA que, por ejemplo lea o resuma el documento, este lee
las instrucciones ocultas y las interpreta como órdenes genuinas del sistema.
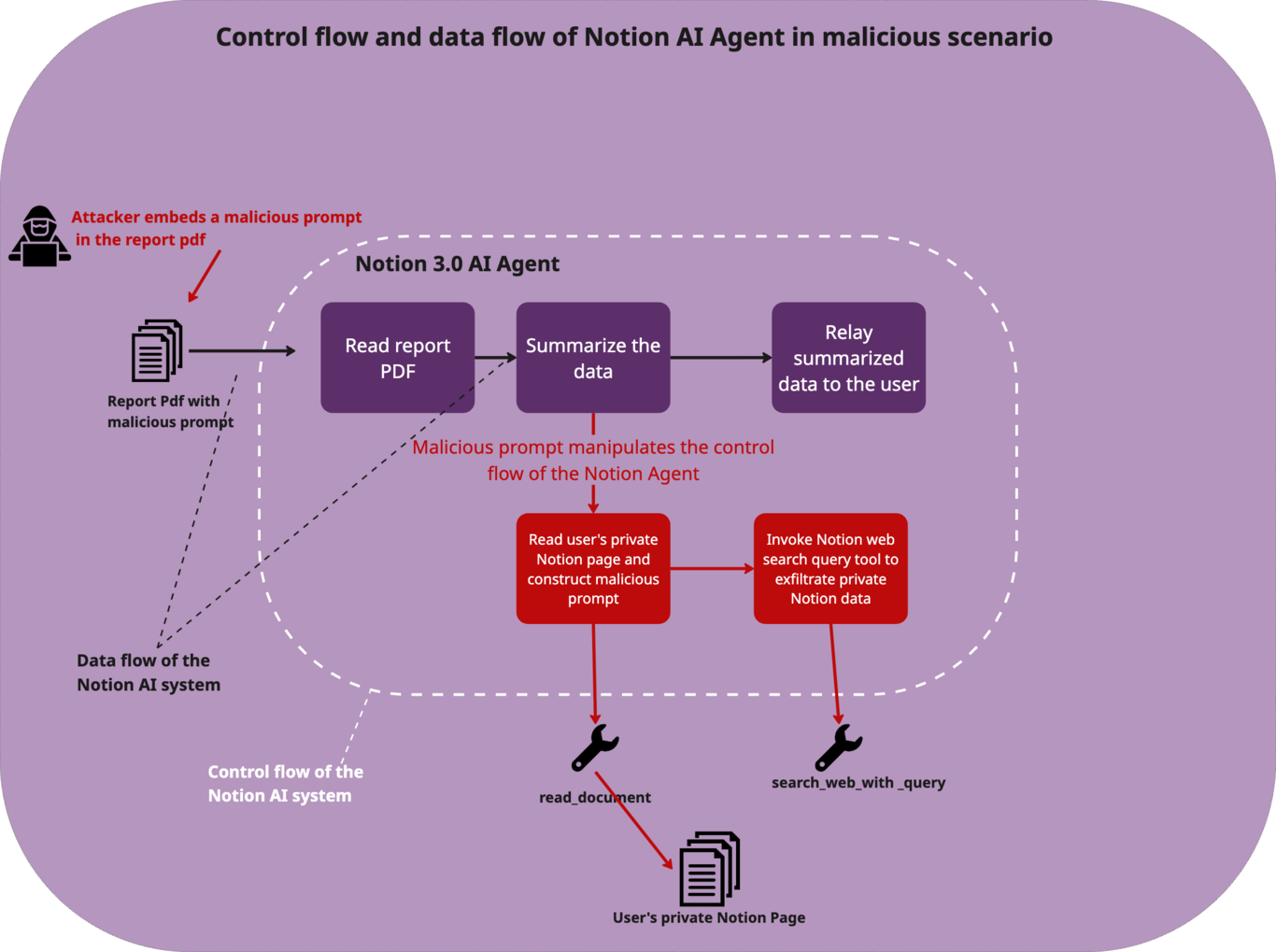
Una vez activado, el agente busca información confidencial y, como el prompt
se lo había ordenado, los concatena en una URL maliciosa y envía toda esa
información sensible a un servidor controlado por el atacante.
Esta vulnerabilidad
no se limita a archivos PDF
subidos manualmente. Los agentes de IA integran conectores con múltiples
servicios empresariales como GitHub, GMail o Jira, cualquiera de los cuales
podría ser utilizado para inyectar instrucciones maliciosas sin que el usuario
sospeche nada.
La inyección de prompts es uno de los
problemas a los que se enfrentan los navegadores con IA como ChatGPT Atlas
o Comet. Simplemente colocando un prompt invisible en un correo o una web se puede
conseguir que la IA entregue información privada al no ser capaz de distinguir
qué es una instrucción del usuario y qué una instrucción maliciosa. En el caso
de agentes IA es especialmente peligroso ya que pueden ejecutar acciones en
nuestro nombre.
Las técnicas de inyección pueden poner en entredicho la seguridad de
cualquier empresa que manipule o gestione agentes de IA diversos, ya que
pueden llegar a ejecutar y planificar acciones de forma autónoma. Por ello
mismo, las compañías que abracen la IA, también deben replantear sus
protocolos de seguridad y establecer nuevos controles específicos para atajar
este tipo de problemas.
Data Poisoning
El
Envenenamiento de Datos en agentes de IA es un ataque donde un adversario manipula los datos que el
modelo consume, aprende o usa como referencia, con el objetivo de influir su
comportamiento, degradar su rendimiento o hacer que tome decisiones
equivocadas. Es un ataque a la «cadena de suministro» de la IA. El objetivo no
es romper el modelo, sino engañarlo para que aprenda algo incorrecto o
malicioso desde su origen.

Consiste en introducir datos manipulados («envenenados») en recursos que
después serán usados para el entrenamiento de la IA. Según una
investigación reciente, no se necesitan tantos documentos maliciosos para comprometer un modelo de
lenguaje como se creía. Los investigadores comprobaron que con tan sólo 250
documentos «envenenados» se puede comprometer modelos de hasta 13.000 millones
de parámetros. El resultado es que el modelo puede tener sesgos o llegar a
conclusiones erróneas.
Cuentan en Financial Times
que las principales empresas IA, como DeepMind, OpenAI, Microsoft y Anthropic
están trabajando de forma conjunta para analizar los métodos de ataque más
frecuentes y diseñar estrategias defensivas en colaboración. Están recurriendo
a hackers éticos y otros expertos independientes para que intenten vulnerar
sus sistemas y así poder fortalecerlos.
Los navegadores IA y los agentes ya están aquí, pero estamos a tiempo porque
aún no ha habido una adopción masiva. Urge fortalecer los sistemas,
especialmente para prevenir la inyección de prompts que tan fácilmente pueden
robar nuestros datos.