
Una nueva investigación de seguridad revela qué categorías de vulnerabilidades se solucionan rápidamente, cuáles no y qué marca la diferencia.
La mayoría de los equipos de seguridad de aplicaciones (AppSec) conocen OWASP Top 10, la lista estándar de la industria de los riesgos de seguridad de software más críticos. Son menos los que saben cuál de esas categorías realmente corrige su organización.
En conversaciones con los equipos de seguridad, escucho la misma historia: «Damos prioridad a los aspectos críticos, para que se manejen las cosas importantes». Los datos cuentan una historia diferente. Las tasas de reparación varían drásticamente según la clase de vulnerabilidad de OWASP y no de la manera que la mayoría de los equipos esperan.
Los datos provienen del informe Remediación a escala de Semgrep, que analizó patrones de remediación anónimos en más de 50.000 repositorios y cientos de organizaciones durante 2025. La metodología es sencilla: agrupar las organizaciones en dos cohortes por tasa fija (el 15% superior como «Líderes», el 85% restante como «Campo»), luego comparar lo que cada grupo realmente hace de manera diferente.
La brecha entre los Líderes y el Campo no tiene que ver con la calidad de la detección o los marcos de priorización. Ambos grupos aplican los mismos filtros de gravedad y presentan los mismos hallazgos críticos. Lo que difiere es la ejecución. Una organización Líder corrige el 63% de sus hallazgos críticos; el otro grupo sólo el 13%. Mismas herramientas. Mismas alertas. Diferentes enfoques.
Las brechas de tipos fijos de las que nadie habla
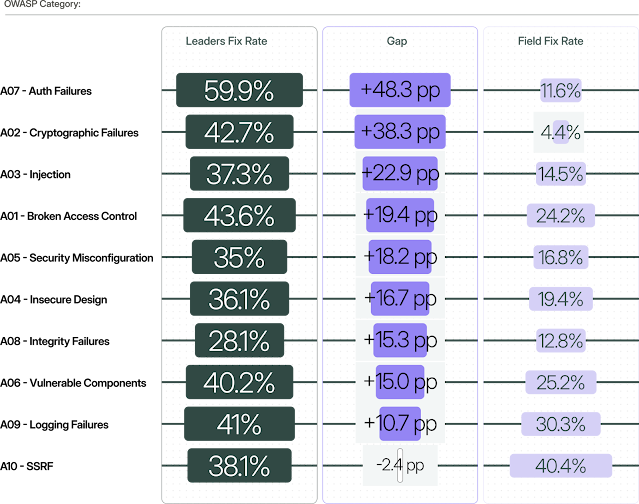
Cuando se dividen las tasas de corrección de las pruebas de seguridad de aplicaciones estáticas (SAST) por categoría OWASP, las mayores brechas entre los equipos de alto rendimiento y todos los demás no están en las categorías que se esperarían.
Los fallos de autenticación (A07) muestran la brecha más grande en el conjunto de datos: una diferencia de 48 puntos porcentuales entre los Líderes y el Campo. Los líderes se sitúan en casi el 60%, mientras que el resto se sitúa en aproximadamente el 12%. Las fallas criptográficas (A02) tienen una diferencia de 38 puntos.

Estas dos categorías comparten un rasgo que puede ser menos evidente solo con la etiqueta OWASP: arreglarlas requiere comprensión arquitectónica, no reemplazo de patrones.
Considere cómo se ve realmente una solución de autenticación. Por lo general, no solo se soluciona un ticket ni se agrega una «verificación la línea 47». Se debe rastrear la gestión de sesiones en todo el middleware, comprendiendo el ciclo de vida de los tokens, auditando la aplicación de múltiples factores y descubriendo cómo funciona el almacenamiento de credenciales en las capas de servicio.
Una solución criptográfica puede significar migrar de un algoritmo obsoleto a uno moderno en todos los sistemas que leen los datos cifrados. Por lo general, se trata de proyectos complicados, no de tickets rápidos.
La SSRF (A10) es una de las únicas categorías donde el Campo supera a los Líderes, mostrando una brecha ligeramente negativa. Las correcciones de SSRF resisten patrones simples porque las listas permitidas se pueden omitir mediante la vinculación de DNS, la codificación de IP y los puntos finales de metadatos en la nube. Ambas cohortes los abordan con un esfuerzo especializado similar, aplanando la brecha observada en otros lugares.
La inyección (A03) se encuentra en el medio con una separación de 23 puntos. La solución en sí (consultas parametrizadas en lugar de concatenación de cadenas) es conceptualmente simple. El desafío es encontrar cada punto de inyección en una base de código grande, particularmente cuando la entrada que no es confiable fluye a través de múltiples archivos antes de llegar a un sumidero peligroso.
Los desgloses más detallados en el informe reflejan esto: cuando un escáner confirma un hallazgo rastreando el flujo de datos entre archivos (análisis entre archivos), los Líderes corrigen esos hallazgos en un 69% frente al 43% para los hallazgos de un solo archivo. Esto significa que cuando los equipos ven el camino completo desde la entrada del usuario hasta el sumidero peligroso, tienden a tratarlo como un trabajo real, mientras que los hallazgos sin evidencia clara del flujo de datos se posponen.
El precipicio de los 90 días: cuando las vulnerabilidades se vuelven permanentes
Los datos también revelan algo que, especialmente para aquellos que gestionan grandes retrasos, debería replantear su forma de pensar sobre los hallazgos de seguridad del código antiguo.
Es poco probable que los hallazgos abiertos durante más de 90 días se solucionen alguna vez. Entre los equipos de alto rendimiento, solo el 9% de las remediaciones de SAST provienen de un trabajo pendiente de más de 90 días. Para el Campo, es el 16%.
Como anécdota, muchos equipos siguen de cerca estos hallazgos trimestre tras trimestre, esperando un buen momento para abordarlos, y ese momento nunca llega. Si una vulnerabilidad ha estado acumulada durante tres meses, la trayectoria predeterminada es que permanezca allí. Trate los 90 días como un punto de escalada, no como una fecha límite sino como una función forzosa. En ese momento, todo hallazgo abierto necesita una de tres disposiciones:
- remediarlo con tiempo dedicado
- aceptar formalmente el riesgo con justificación documentada
- silenciarlo como un falso positivo confirmado
Dejar que los hallazgos permanezcan indefinidamente sin tomar una decisión no es gestión de riesgos.
Qué hacen de manera diferente los equipos de alto rendimiento
Los patrones que separan a los Líderes del Campo generalmente implican algún tipo de configuración del flujo de trabajo, no solo la selección de herramientas.
Si separamos las vulnerabilidades del código mediante vulnerabilidades de código propio (SAST) y vulnerabilidades introducidas por paquetes y dependencias (SCA), podemos ver que hay una serie de ideas interesantes:
El escaneo a nivel de relaciones públicas acelera la corrección 9 veces, pero solo si el flujo de trabajo lo admite. El 96% de los Líderes y el 95% de las organizaciones de Campo ya ejecutan escaneos SAST y SCA en solicitudes de extracción (el código revisa que los desarrolladores abren antes de fusionar los cambios).
La adopción del escaneo en los Pull Request (PR) no es el diferenciador. Lo que difiere es si los hallazgos son procesables en el momento de la solicitud para incorporar el código. Los Líderes resuelven los hallazgos SAST detectados en los PR en un promedio de 4,8 días; el mismo tipo de hallazgo en una exploración completa tarda 43 días.
Entre las organizaciones Líderes, el 63 % de las correcciones detectadas en PR ocurren el mismo día. Esto tiene sentido cuando se piensa en la experiencia del desarrollador: ya están en el código, el contexto es nuevo y la solución se envía en el mismo PR sin necesidad de ticket ni reasignación.
Las reglas de bloqueo generan el mayor aumento de correcciones en el conjunto de datos. Las organizaciones que configuran reglas específicas de alta confianza para bloquear fusiones de código, ven resultados mensurables: los Líderes obtienen una mejora de 12 puntos porcentuales en la tasa de corrección de SAST y SCA; el Campo gana 5 puntos.
¿A qué se debe tal disparidad? La diferencia es que los Líderes han creado el flujo de trabajo posterior para respaldar una fusión bloqueada: el desarrollador sabe qué arreglar, la ruta de solución es inequívoca y el bloqueo no se trata como ruido para anular. Restringen el bloqueo a reglas en las que eso es cierto (secretos codificados, inyección de SQL mediante concatenación de cadenas, falta de autenticación en puntos finales sensibles) y evitan el bloqueo de reglas con altas tasas de falsos positivos.
El análisis de accesibilidad transforma la priorización de SCA. El conjunto de datos no solo incluye hallazgos de SAST, sino que también incluye hallazgos relacionados con paquetes de terceros gracias a Semgrep Supply Chain.
Para las vulnerabilidades de dependencia, saber que un paquete contiene un exploit versus saber si su código base realmente llama a la función vulnerable dentro del paquete cambia el comportamiento. Los Líderes fijan los hallazgos alcanzables de SCA en un 92% frente al 67% de los hallazgos no alcanzables. Esta señal elimina la fatiga de las alertas de dependencia al separar lo que está técnicamente presente de lo que realmente es explotable.
Por donde empezar
Si está intentando comparar su propio programa, el informe ofrece un diagnóstico simple: observe su tasa de corrección SAST crítica. Si está por debajo del 50%, es probable que el problema no sea la calidad de la detección. Algo entre la detección y la remediación está roto. En mi experiencia, suele ser una de tres cosas: los hallazgos no llegan a los desarrolladores con suficiente contexto; no hay un propietario claro para cada hallazgo o; no hay una ruta de escalamiento para los problemas antiguos.
El informe completo de Remediación a escala de Semgrep incluye un análisis de tasa de corrección realizado por CWE (Common Weakness Enumeration, una clasificación más detallada que OWASP), datos específicos del ecosistema en varios administradores de paquetes y un conjunto priorizado de recomendaciones organizadas por cronograma de implementación.
Fuente: THN